这个故事是十大网博靠谱平台一个人工智能驱动的顾问聊天机器人的,我是基于它工作的 LangChain 和 Chainlit. 这个机器人向潜在客户询问他们在企业数据空间中的问题, 开发动态调查问卷,以便更好地了解问题. 在收集了用户问题的足够信息后,它给出了解决问题的建议. 在提出问题的同时,它还试图检查用户是否感到困惑,是否需要回答一些问题. 如果是这种情况,它会尝试回复它.
聊天机器人是围绕与人工智能治理相关主题的知识库构建的, 安全, 数据质量, 等. 但你也可以选择其他话题.
该知识库存储在矢量数据库(做),并在每个步骤中用于提出问题或提供建议.
然而,这个聊天机器人可以基于任何知识库,并在不同的环境中使用. 所以你可以把它作为其他咨询聊天机器人的蓝图.
交互流
聊天机器人的正常流程很简单:用户提问,机器人回答,以此类推. 机器人通常会记住之前的互动,所以有一个历史记录.
然而,这个机器人的交互是不同的. 它是这样的:
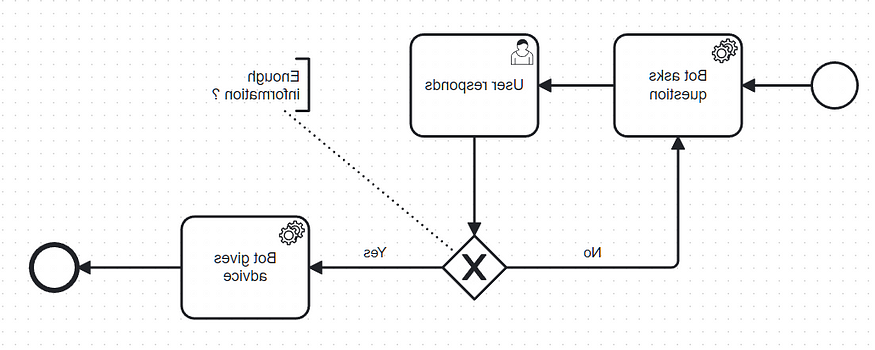
人工智能驱动的顾问聊天机器人互动
在这种情况下,聊天机器人会问一个问题, 用户回答并重复这个交互几次. 如果积累的知识足以回答问题或问题的数量达到一定的阈值, 给出一个回应, 否则就会问另一个问题.
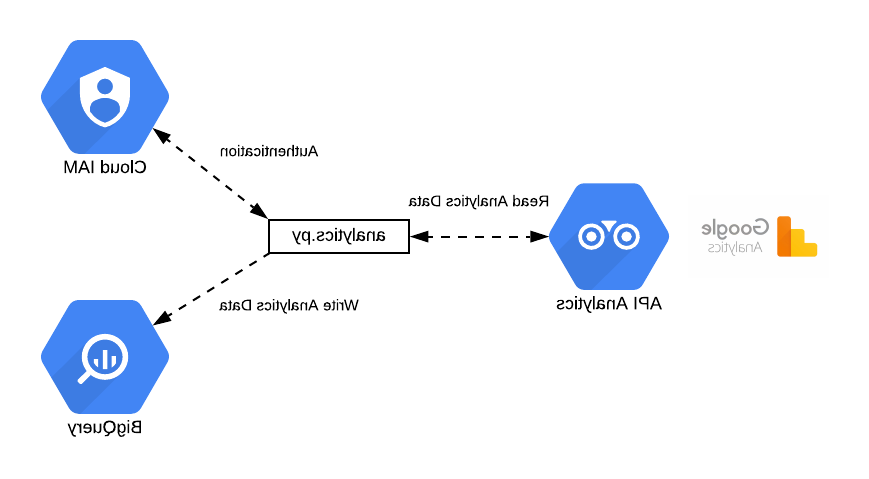
粗略的体系结构
以下是该应用程序的参与者:

主要参与者是人工智能驱动的顾问聊天机器人
我们有4个参与者:
用户
在ChatGPT、知识库和用户之间协调工作流的应用程序.
ChatGPT 4 (gpt-4-0613)
知识库(采用矢量数据库) 做)
我们已经尝试了ChatGPT 3.但结果不是很好,很难产生有意义的问题. ChatGPT 4 (gpt-4-0613)似乎提供了更好的问题和建议,也更稳定.
我们还试验了最新的ChatGPT 4模型(gpt-4 - 1106预览版), GPT 4 Turbo), 但是我们经常从OpenAI函数调用中遇到意想不到的结果. 所以我们经常会看到这样的错误日志:
文件“pydantic /主要.Py ",第341行,pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError:响应标签的2个验证错误
extracted_questions
必需的字段(type=value_error).失踪)
questions_related_to_data_analytics
必需的字段(type=value_error).失踪)
工作流-它是如何工作的
下图显示了该工具的内部工作原理:

聊天机器人工作流
以下是工作流程的步骤:
该工具向用户询问一个预定义的问题. 这是典型的:”
在你的数据生态系统中,你最关心的是哪个领域?”用户回答最初的问题
聊天机器人检查用户的回复是否包含一个合法的问题.e. 一个不离题的问题)
-如果是,则启动一个简单的查询代理来澄清问题. 这个简单的代理使用ChatGPT 4和DuckDuckGo搜索引擎.现在聊天机器人决定是提出更多的问题还是给出建议. 这个决定受到一个简单规则的影响:如果问题少于4个, 还有一个问题, 否则,我们让ChatGPT决定是给出建议还是继续提问.
-如果决定继续问问题, 查询带有知识库的向量数据库以检索与用户答案最相似的文本. 向量数据库搜索结果包含问题和答案,并发送给ChatGPT 4以生成更多问题.
—如果决策是给出建议,则查询知识库中的所有问题和答案. 知识库中最相似的部分被提取出来,并与整个问卷(问题和答案)一起包含在ChatGPT的建议生成提示中. 给出建议后,流程终止.
实现
整个实现可以在这个存储库中找到:
GitHub - onepointconsulting/ Data - Questionnaire - 代理:数据问卷代理聊天机器人
项目的安装说明可以在项目的README文件中找到:
http://github.com/onepointconsulting/data-questionnaire-agent/blob/main/README.md
应用程序模块
bot包含一个服务模块,您可以在其中找到与ChatGPT 4交互并执行某些操作的所有服务, 比如生成PDF报告和向用户发送电子邮件.
服务
这是包含服务的文件夹:
最重要的服务是:
咨询服务 -创建Langchain LLMChain 用于生成建议. LLMChain使用 OpenAI功能,就像这个应用程序中的大多数链一样. 此函数的输出模式在 openai_schema.py文件.
嵌入服务 -从知识库中创建基于OpenAI的嵌入,知识库应该是一个文本文档列表.
html发电机 -用于生成email和PDF格式的HTML函数
邮件发送者 -用来发送电子邮件.
问题生成服务 -用于生成除第一个生成的问题外的所有问题. 它还使用了Langchain LLMChain 与 OpenAI功能.
相似性搜索 - used使用 做. 最有趣的函数是similarity_search函数,它执行多次搜索,以最大化发送到ChatGPT 4的令牌数量,直到达到限制
标签服务 -用来判断用户在回答问题时是否有合法的问题. 在这项服务中,我们使用的是LangChain的 create_tagging_chain_pydantic 方法生成标记链.
数据结构
在这个应用程序中有一个数据结构模块:
在这种情况下,我们有两个模块:
用户界面
这是一个模块 Chainlit 基于用户界面代码:
http://github.com/onepointconsulting/data-questionnaire-agent/tree/main/data_questionnaire_agent/ui
该文件用主实现的 Chainlit 用户界面为:
data_questionnaire_chainlit.py. 它包含应用程序的主要入口点以及运行代理的逻辑.
该文件中包含工作流实现的方法是process_questionnaire.
十大网博靠谱平台UI的注意事项
Chainlit版本是从版本0派生出来的.7.0和修改以满足给我们的一些要求. 该项目应该工作,但使用更现代的Chainlit版本.
提示
我们将提示符从Python代码中分离出来,并使用 toml 存档:
http://github.com/onepointconsulting/data-questionnaire-agent/blob/main/prompts.toml
提示符使用分隔符将que指令与知识库、问题和答案分开. 与ChatGPT 3不同,ChatGPT 4似乎能够很好地理解分隔符.5,这很容易混淆. 下面是一个用于生成问题的提示符的例子:
(问卷调查)
(调查问卷.最初的)
在你的数据生态系统中,你最关心的是哪个领域?"
system_message =“您是数据集成和治理专家,可以询问有关数据集成和治理的问题,以帮助客户解决数据集成和治理问题”
human_message = """基于最佳实践和知识库以及对客户回答的问题的回答, \
请生成有助于该客户解决数据集成和治理问题的{questions_per_batch}问题.
最佳实践部分从==== best practices START ====开始,以==== best practices END ====结束.
知识库部分以==== knowledge base START ====开始,以==== knowledge base END ====结束.
向用户提出的问题以==== question ====开始,以==== question END ====结束.
客户提供的用户回答以==== answer ====开头,以==== answer END ====结尾.
====知识库启动====
{knowledge_base}
====知识库端====
====问题====
{问题}
====问题结束====
====回答====
{答案}
====回答结束====
"""
(调查问卷.二次)
system_message =“您是一名英国数据集成和治理专家,可以询问有关数据集成和治理的问题,以帮助客户解决数据集成和治理问题”
human_message = """基于最佳实践和知识库以及客户回答的多个问题的答案, \
请生成有助于该客户解决数据集成问题的{questions_per_batch}问题, 治理和质量问题.
知识库部分以==== knowledge base START ====开始,以==== knowledge base END ====结束.
客户回答的问题和回答部分以====问卷====开始,以====问卷结束====结束.
用户答案位于以==== answers ====开始,以==== answers END ====结束的部分中.
====知识库启动====
{knowledge_base}
====知识库端====
====问卷====
{questions_answers}
====问卷结束====
====回答====
{答案}
====答案结束====
"""
如您所见,我们正在使用分隔符部分,如e.g: ====知识库开始====或====知识库结束====
外卖
我们尝试使用ChatGPT 3构建有意义的交互.5, 但是这个模型不能很好地理解提示分隔符, 而ChatGPT 4 (gpt-4-0613)可以做到这一点,并允许我们与用户进行有意义的交互. 因此,我们为这个应用程序选择了ChatGPT 4.
就像我们之前提到的, 我们尝试用gpt-4 - 1106预览版替换gpt-4-0613, 但结果并不好. 函数调用经常失败.
当我们开始这个项目时,我们每分钟有10000个令牌的限制,这导致了一些恼人的错误. 但现在OpenAI将限制增加到30万个令牌,这增加了应用程序的稳定性:

增加了每分钟令牌的限制
另一个重要的收获是,你需要非常小心地限制互动的范围, 否则你的机器人可能会被误用, 就像这个例子:

离题问题
但是我们找到了一种方法来防止它,并且机器人可以识别离题问题(参见[标签]部分) promps.toml 文件):

最后的结论是,ChatGPT4能够应对这一挑战,生成一种有意义的顾问式交互,它可以生成一个开放式问卷,以一系列有意义的建议结束.